Language models solve complex problems by articulating intermediate reasoning steps in natural language. While effective, this process is computationally bottlenecked: each reasoning step conveys only a single subword, and many are spent expressing a thought instead of carrying out computation.
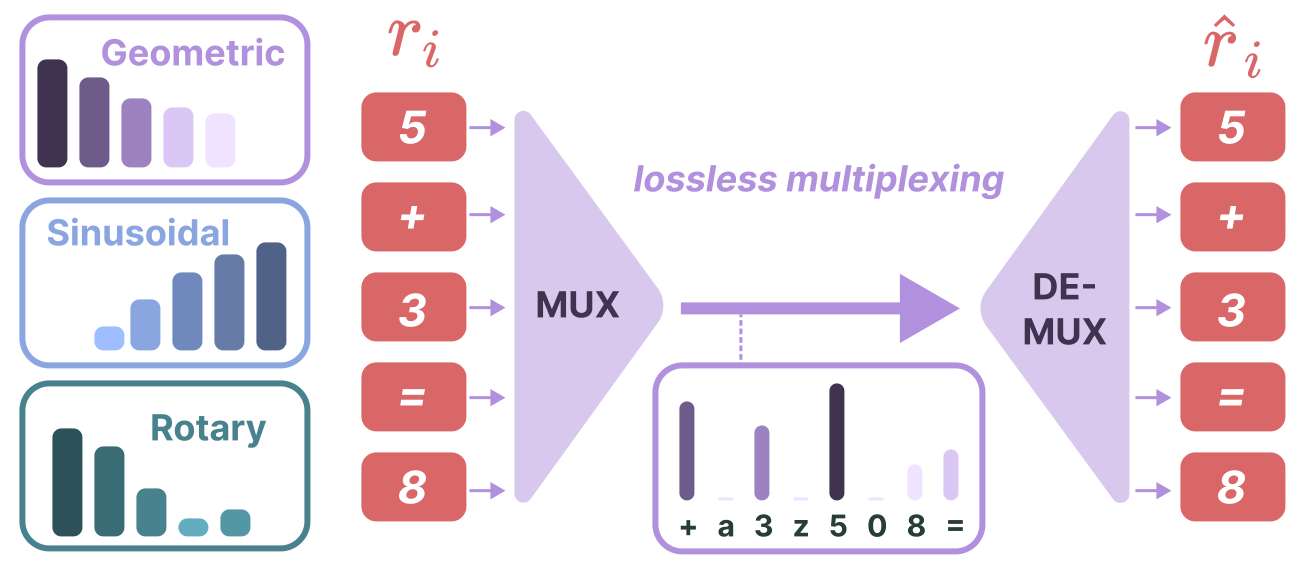
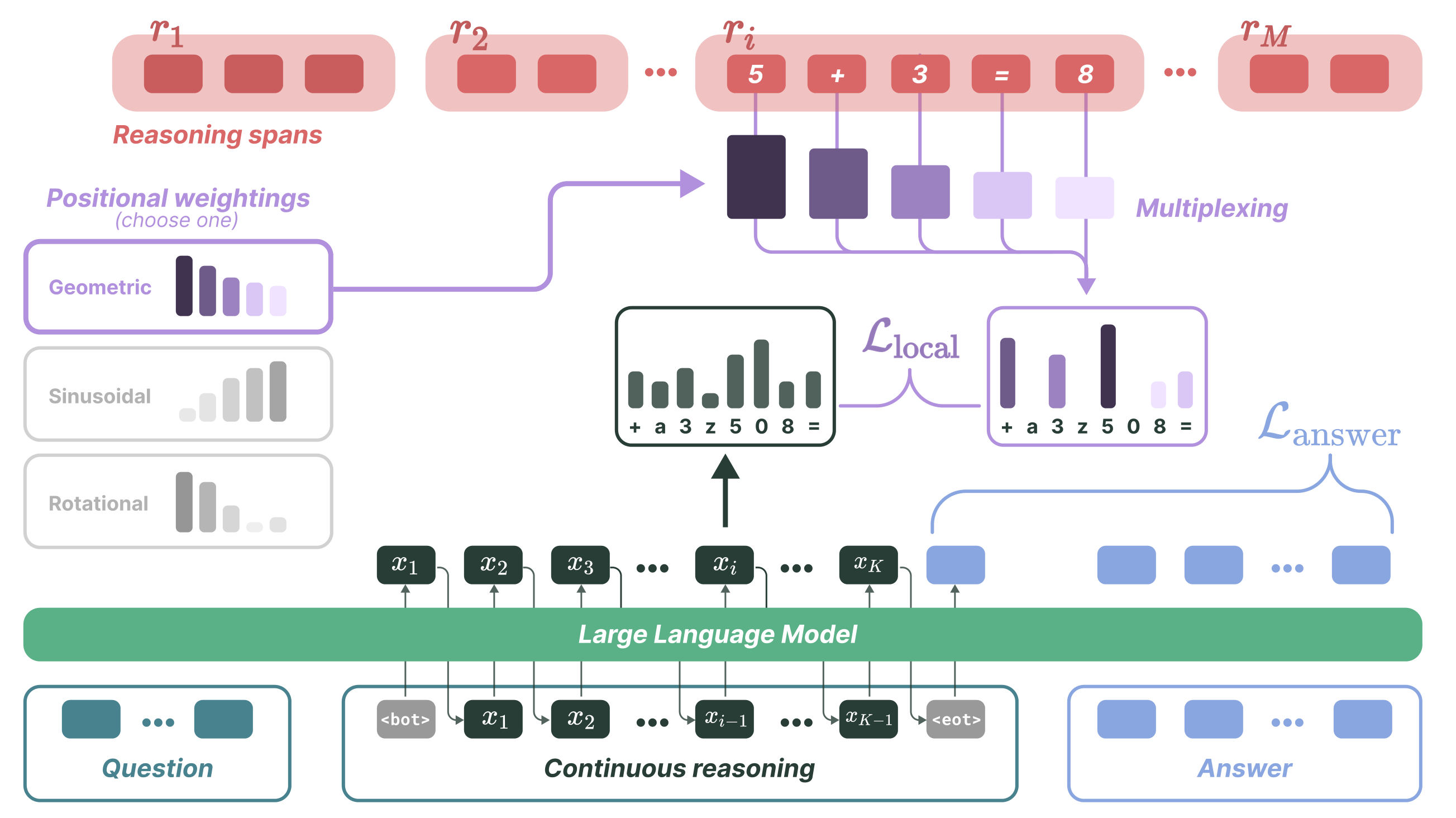
We propose MUX, a simple method for high-bandwidth and compact reasoning based on distillation of discrete reasoning into continuous multiplexed tokens in a latent space. Here, each latent token is trained to represent a weighted linear superposition (multiplexing) of a span of discrete reasoning subwords, where this superposition is lossless by construction and the span can be fully recovered (demultiplexing).
We prove that simple position-dependent weightings, such as suitable geometric decay, support lossless multiplexing, which in turn prevents shortcut behaviors caused by latent collapse. We further show that multiplexed reasoning can perform parallel exploration in problems that require search.
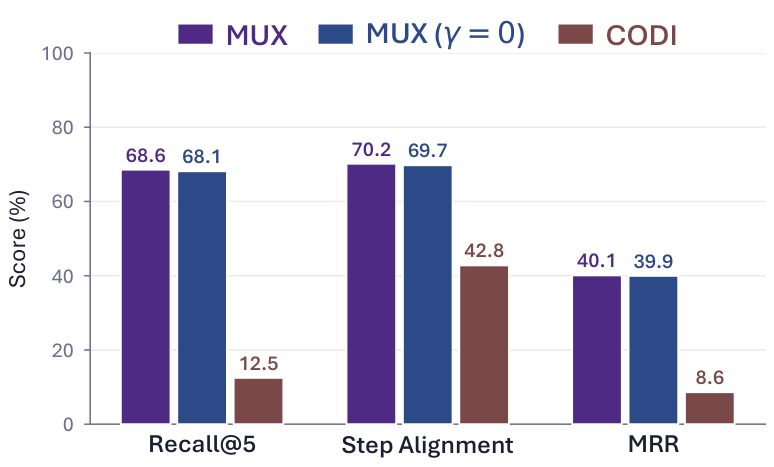
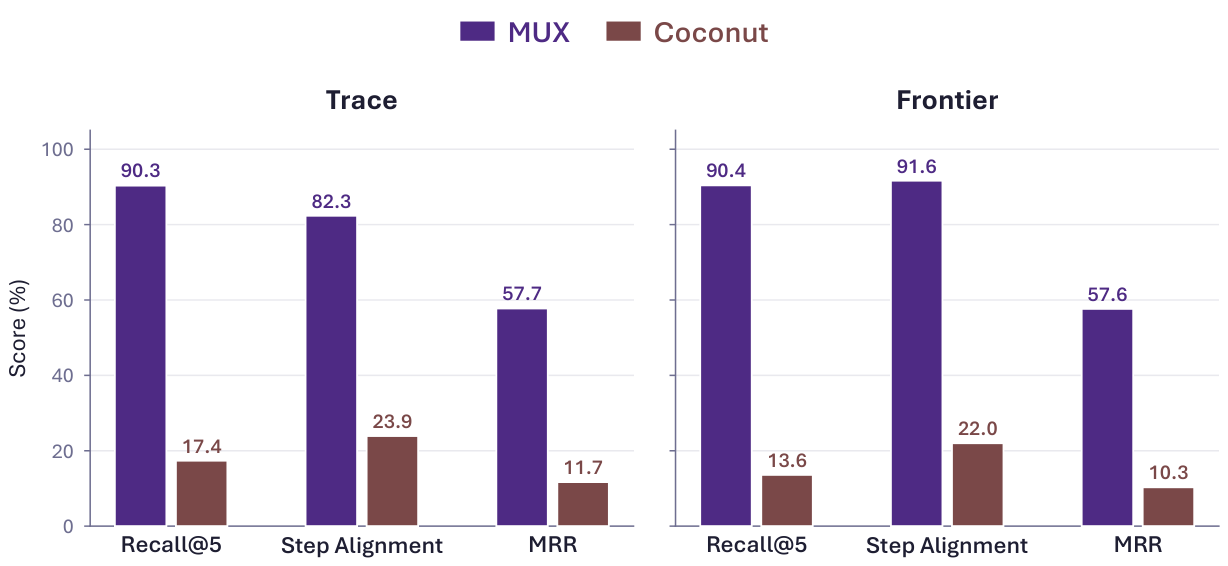
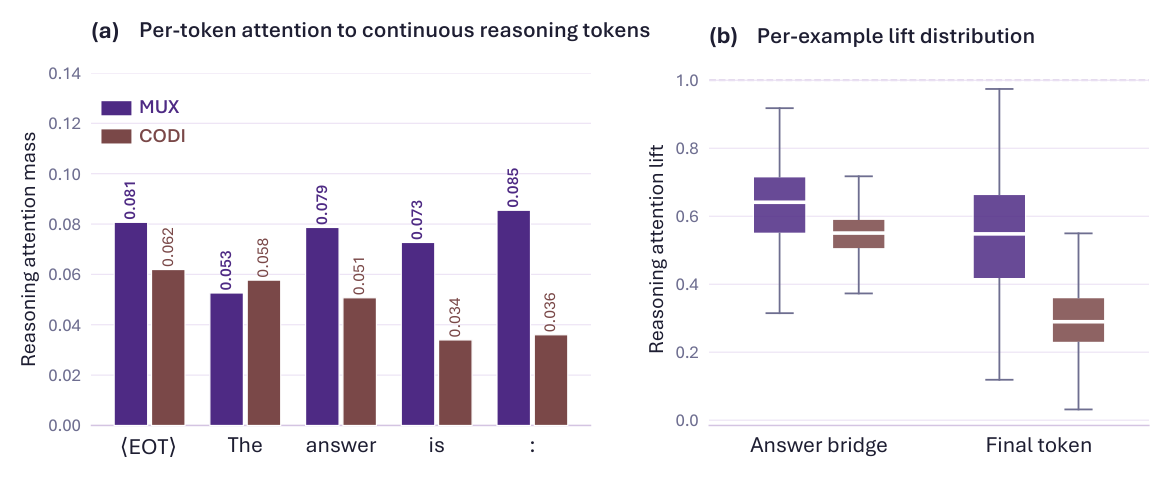
Across 32 evaluation settings spanning four language models, MUX outperforms strong latent reasoning baselines. Ablation and probing analyses further show that the learned latent tokens encode faithful and interpretable reasoning. Our results suggest that lossless superposition as local learning targets constitutes a sufficient condition for achieving strong and efficient latent continuous reasoning.